Our research computing cluster at work is slowly gathering more users, more storage, more applications, more physical machines etc. Managing everything consistently and predictably was beginning to get complicated (or maybe I’m just getting old?). There’s lots of buzz in DevOps circles about tools for managing this kind of scenario; Chef, Salt, Puppet and Ansible are all tools which fit into the semi-related configuration management, infrastructure orchestration, and automation categories.
Ansible is the newest tool in this arena, and I liked it because it didn’t require any daemons or centralized databases, etc; it piggybacks ontop of SSH and can use your existing key-less authentication to connect to your machines (you are using SSH keys for authentication, aren’t you?).
Click here for TL;DR. 🙂
Ansible playbook layout
I had been experimenting with Ansible to do a few one-off tasks predictably and remotely (like install apache2 or to copy a standardized /etc/apt/sources.list), but the real power of ansible comes from organizing and classifying your infrastructure and then writing “playbooks” to represent common tasks and workflows. I started to think about my infrastructure’s physical hardware and the roles I could reduce the machines to, ie “storage”, “compute”, “web”, etc, as well as properties that were “common” between them.
Starting from scratch is always hard, but luckily the Ansible Best Practices guide is a great place to look first. Also, the Fedora Project’s infrastructure repo is a rather large, public example of a working ansible deployment with many, many playbooks you can check out.
Inspired by those examples, I laid out the ansible playbooks for our research computing infrastructure like this:
├── LICENSE
├── README.md
├── compute.yml
├── group_vars
│ ├── compute
│ └── storage
├── hosts
├── roles
│ ├── common
│ │ ├── files
│ │ ├── handlers
│ │ │ └── main.yml
│ │ ├── tasks
│ │ │ ├── iptables.yml
│ │ │ └── main.yml
│ │ └── templates
│ │ └── iptables.j2
│ ├── ganglia
│ │ ├── files
│ │ │ └── gmetad.conf
│ │ ├── handlers
│ │ │ └── main.yml
│ │ ├── tasks
│ │ │ ├── gmetad.yml
│ │ │ ├── gmond.yml
│ │ │ └── main.yml
│ │ └── templates
│ │ └── gmond.conf.j2
│ ├── glusterfs
│ │ ├── files
│ │ │ ├── 65-scheduler.rules
│ │ │ └── glusterfs-epel.repo
│ │ ├── handlers
│ │ │ └── main.yml
│ │ ├── tasks
│ │ │ ├── client.yml
│ │ │ ├── main.yml
│ │ │ └── server.yml
│ │ └── templates
│ │ └── sshd_config.j2
│ └── sssd
│ ├── files
│ │ └── etc
│ │ └── openldap
│ │ ├── cacerts
│ │ │ └── hpc-ca.asc
│ │ └── ldap.conf
│ ├── handlers
│ │ └── main.yml
│ ├── tasks
│ │ ├── main.yml
│ │ ├── openldap.yml
│ │ └── sssd.yml
│ └── templates
├── site.yml
└── storage.ymlThat should give you a bit of an idea how to start.
Breaking [some of] it down
A snippet from my top-level hosts file:
[storage]
storage0.ilri.cgiar.org
storage1.ilri.cgiar.org
storage2.ilri.cgiar.orgAnd my storage.yml file has this:
---
# file: storage.yml
- hosts: storage
sudo: yes
roles:
- common
- ganglia
- sssd
- glusterfsThis means that my storage servers should run the following roles: common, ganglia (for monitoring), sssd (for LDAP auth), and glusterfs (for network mounts, like /home).
Each of those roles have some or all of the following properties:
- files — static files, such as
ldap.conf, which are the same on every server which needs them - handlers — sets of named tasks, such as restart iptables, which would live in
iptables.yml(included frommain.yml); these are called bynotifyactions in tasks - tasks — lists of actions, such as installing packages, running scripts, etc, and are included starting from
main.yml - templates — templated configuration files, such as
iptables.j2orgmond.conf.j2, which might differ based on the server group or specific host in question
I follow a similar paradigm for my compute servers; the roles are slightly different but the concept is exactly the same.
What this gets me
This gives me the ability to manage my budding infrastructure according to host groups and server roles. I can, for example, redeploy the firewall settings on all my storage servers with one command:
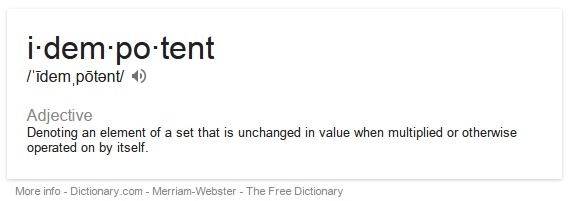
ansible-playbook storage.yml -K --tags=firewall… and with that the iptables configurations on all my storage servers are idempotently updated. Idempotence means that running the command over and over should result in the same outcome. If the iptables configuration needs an update, it is updated. If it doesn’t, it isn’t.
Errr…
BTW, using --tags allows me to run a subset of tasks, rather than running all the tasks associated with a storage server’s roles.
The takeaway
Reducing common tasks into succinct, predictable and reproducible processes via ansible playbooks isn’t just good business, it’s fun! Computing is all about the users, their data and their applications, the hardware where those things “live” is of little importance. Tools like ansible allow you to place your infrastructure into inventory groups and abstract their functionality into roles.
The next step for me is to expand the use of ansible in my infrastructure. To be honest, I don’t deploy new servers all that often, but I like the way writing ansible playbooks makes me think; idempotence is a powerful concept! I don’t want any variables in the deployment process. I want to be able orchestrate systems and services precisely, and to be able to build upon those processes without having to start from scratch every time I bring up a new machine.
I’ve had a few “Ah-hah” moments since I started playing with ansible, so I plan on writing more about those soon!
How does one get the initial OS installed on the client machines? Are the options just manual installation and PXE?
Adam, for my virtual machines I write kickstarts and use KVM command lines like:
The kickstart has my user account + password hash already in it, so I can ansible out of the box.
For physical machines it’s a bit more annoying, you can still use kickstarts but it requires DHCP + PXE to be set up, and also you need to go find the MAC address of the NIC, and some other annoying things which happen on physical machines that don’t happen on VMs (like when you have many physical disks and you want to use the 250GB one as / and the 33TB RAID array for gluster, you can’t depend on /dev/sda always being the same drive!).
Hi, very nice writup thank you.
Any chance you can show us more about your sssd tasks ? How do you manage idempotence here ? Do you provide full configuration or use some kind of helpers ?
Yeah, I’ll make that my next topic! Also, regarding idempotence for SSSD, I haven’t had any problems, but I haven’t tested extensively. Using config files is hard because you have to mess with /etc/nsswitch.conf and /etc/pam.d/* etc… I am just using one big, long authconfig command.
More later!