I recently rolled out a new distributed model for our research computing cluster at work. We’re using GlusterFS for networked home directories and SLURM for job/resource scheduling. GlusterFS allows us to scale storage with minimal downtime or service disruption, and SLURM allows us to treat compute nodes as generic resources for running users’ jobs (ie, users’ homes are “everywhere”, so it doesn’t matter where the jobs run).
Happy sysadmin
We’re currently holding a bioinformatics training at the ILRI Nairobi campus, with about twenty-five attendees from Kenya and elsewhere in East Africa. This morning I logged into the cluster and was happy to see that the users are using the job scheduler to get interactive shells on taurus, one of our compute nodes:
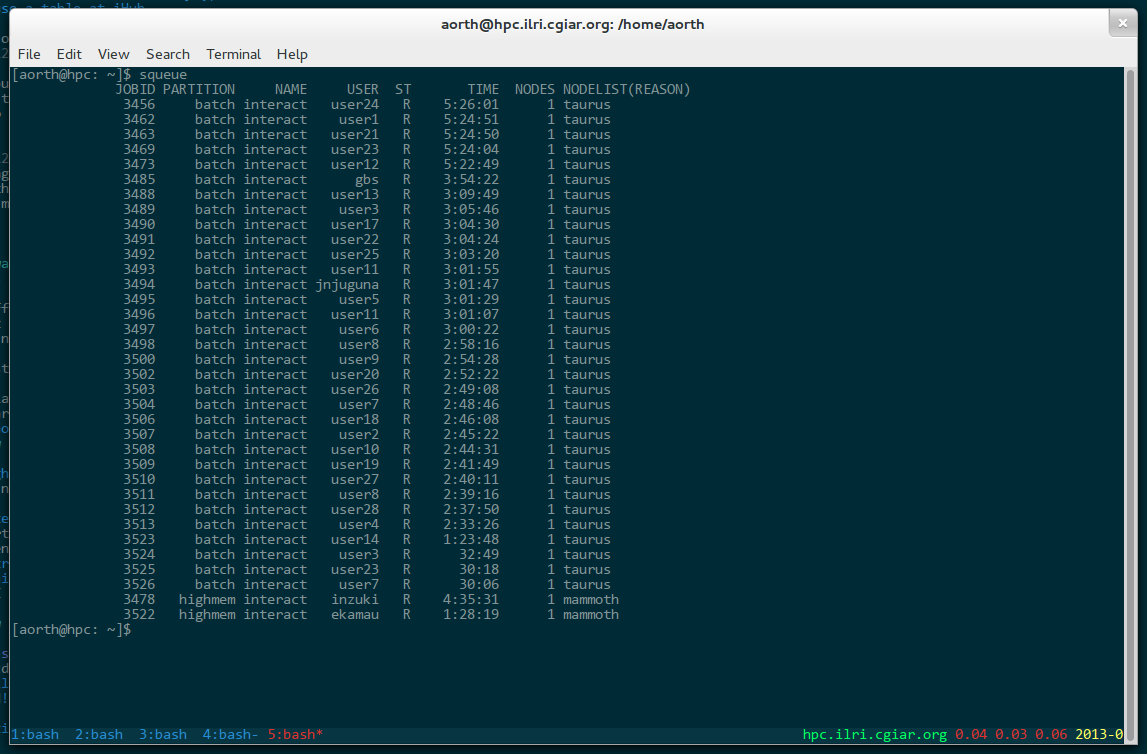
taurus is the main machine in our batch queue, and has 64 compute cores. Also, a few of our “normal” users are using mammoth (the main machine in our highmem queue).
It feels good to see a system you designed work properly!