Today Munin was complaining that a partition is nearly full on one of my servers. Looking at the disk usage graph it kinda seems like a slow loris DOS attack…
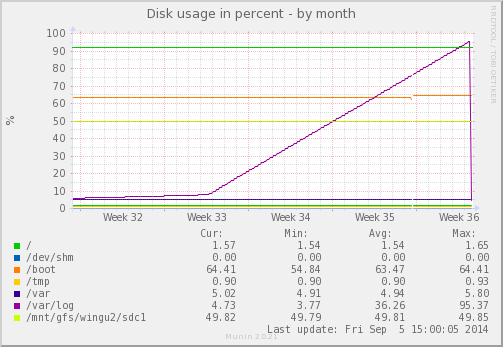
Sure enough, something has gone and filled up the /var/log partition:
$ df -h /var/log/
Filesystem Size Used Avail Use% Mounted on
/dev/mapper/vg_root-log
9.9G 9.0G 446M 96% /var/logProbably logs from GlusterFS…
$ du -sh /var/log/glusterfs/* | sort -hr | head -n1
8.6G /var/log/glusterfs/export-data-mirror.logYep, typical. I see this a few times a month: a glusterfs process on a client writes a metric ton of messages to the FUSE mount’s log file. Looking through the file, I find 4+ million lines like this:
[2014-09-05 05:08:47.994453] I [dict.c:370:dict_get] (-->/usr/lib64/glusterfs/3.5.2/xlator/performance/md-cache.so(mdc_lookup+0x318) [0x7fd3c79ec518] (-->/usr/lib64/glusterfs/3.5.2/xlator/debug/io-stats.so(io_stats_lookup_cbk+0x113) [0x7fd3c77d1c63] (-->/usr/lib64/glusterfs/3.5.2/xlator/system/posix-acl.so(posix_acl_lookup_cbk+0x233) [0x7fd3c75c33d3]))) 0-dict: !this || key=system.posix_acl_defaultAs far as I can tell this is an informational message (denoted by the I prefix), as opposed to an error or a warning… so let’s delete the file.
Reclaim the space
To reclaim the space used by the log file you will have to rip it from Gluster’s teeth — the glusterfs process still has the file descriptor open, so if you just remove it the disk space won’t be reclaimed.
To force the process to release the old file handle and grab a new one, send it a HUP signal:
$ sudo rm -f /var/log/glusterfs/export-data-mirror.log
$ sudo killall -HUP glusterfs
$ df -h /var/log/
Filesystem Size Used Avail Use% Mounted on
/dev/mapper/vg_root-log
9.9G 361M 9.0G 4% /var/logshrug. I hope that wasn’t an important error. In any case, you’re welcome, future travelers. 😉